
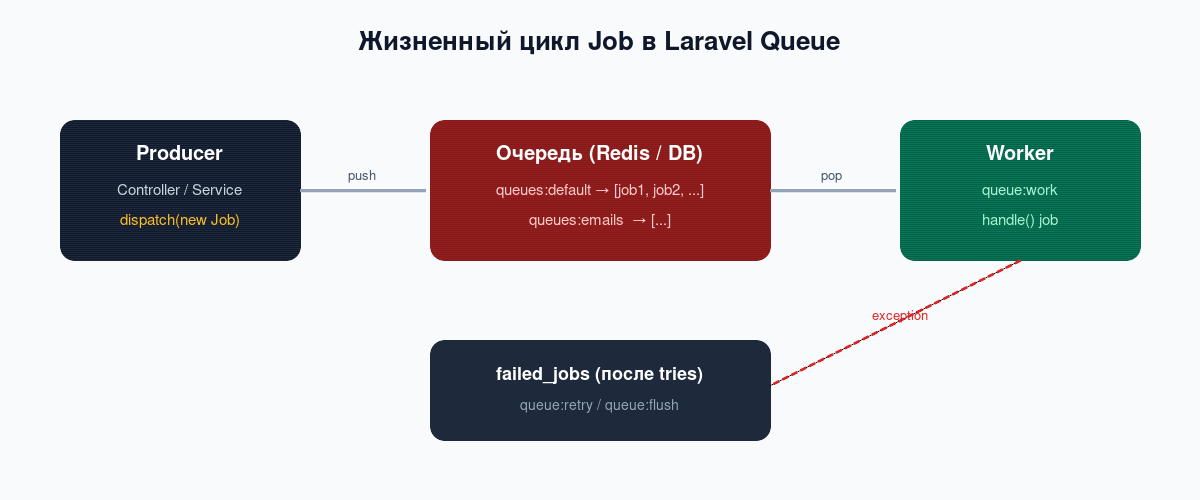
Когда контроллер отправляет письмо, генерирует PDF или дёргает внешний API, пользователь ждёт ответ сервера всё это время. Очереди в Laravel переносят такую работу в отдельный процесс: контроллер за миллисекунды кладёт задачу в Redis, а воркер забирает и выполняет её в фоне. Разберём, как настроить драйвер, написать Job, запустить воркер через Supervisor и не потерять задачи при падении.
Драйверы очередей и какой выбрать
Laravel поддерживает несколько драйверов: sync (выполнение в том же процессе — для отладки), database (хранение в таблице MySQL), redis, beanstalkd, sqs. На небольших проектах рабочая связка — Redis: атомарные операции LPUSH/BRPOP, поддержка отложенных задач через ZSET, низкая задержка.
Базовая конфигурация в config/queue.php:
'default' => env('QUEUE_CONNECTION', 'redis'),
'connections' => [
'redis' => [
'driver' => 'redis',
'connection' => 'default',
'queue' => env('REDIS_QUEUE', 'default'),
'retry_after' => 90, // секунд до повторной выдачи воркеру
'block_for' => 5, // блокирующее ожидание новой задачи
'after_commit'=> true, // диспатчить после коммита транзакции
],
],Параметр retry_after важен: если задача выполняется дольше этого значения, очередь решит, что воркер умер, и выдаст её ещё раз. Делайте retry_after заведомо больше, чем самый долгий handle(), иначе одна задача выполнится дважды.
Для database драйвера нужна таблица jobs — её создаёт миграция:
php artisan queue:table
php artisan queue:failed-table
php artisan migrateСоздание Job и dispatch
Job — это класс с методом handle(), в который Laravel передаёт зависимости через контейнер. Генерируется командой:
php artisan make:job SendOrderConfirmationВнутри — конструктор с данными и сама логика. Важно: данные сериализуются в очередь, поэтому передавайте идентификаторы моделей, а не объекты целиком. Иначе при изменении схемы старые задачи могут не распакеоваться.
<?php
namespace App\Jobs;
use App\Models\Order;
use App\Services\Mailer;
use Illuminate\Bus\Queueable;
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Foundation\Bus\Dispatchable;
use Illuminate\Queue\InteractsWithQueue;
use Illuminate\Queue\SerializesModels;
class SendOrderConfirmation implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
// Сколько раз пробовать перед попаданием в failed_jobs
public int $tries = 3;
// Жёсткий тайм-аут на handle() в секундах
public int $timeout = 60;
// Задержки между попытками (экспоненциальный backoff)
public function backoff(): array
{
return [10, 30, 120];
}
public function __construct(public int $orderId) {}
public function handle(Mailer $mailer): void
{
$order = Order::with('user', 'items')->findOrFail($this->orderId);
$mailer->send($order->user->email, 'order.confirmed', ['order' => $order]);
}
// Вызывается, когда задача окончательно упала после всех tries
public function failed(\Throwable $e): void
{
\Log::error('Order confirmation failed', [
'order_id' => $this->orderId,
'error' => $e->getMessage(),
]);
}
}Диспатч из контроллера — три способа. Простой:
// Сразу в очередь по умолчанию
SendOrderConfirmation::dispatch($order->id);
// На именованную очередь
SendOrderConfirmation::dispatch($order->id)->onQueue('emails');
// С задержкой в 5 минут
SendOrderConfirmation::dispatch($order->id)->delay(now()->addMinutes(5));
// Только если транзакция БД успешно закоммитилась
DB::transaction(function () use ($order) {
$order->update(['status' => 'paid']);
SendOrderConfirmation::dispatch($order->id)->afterCommit();
});Метод afterCommit() спасает от классической ошибки: воркер успевает забрать задачу до того, как родительская транзакция закоммитилась, и видит данные как они были до изменений.
Запуск воркера и Supervisor
В разработке достаточно одной команды:
php artisan queue:work redis --queue=default,emails --tries=3 --timeout=60 --sleep=3Параметры по порядку: redis — имя соединения, --queue — список очередей через запятую (воркер обрабатывает по приоритету слева направо), --tries — глобальное число попыток, --timeout — жёсткий лимит на задачу через pcntl_alarm, --sleep — пауза, если очередь пуста.
На проде один queue:work в фоне — это путь к падениям. Воркер должен перезапускаться после крашей, после изменения кода и после превышения лимита памяти. Для этого используют Supervisor. Конфиг в /etc/supervisor/conf.d/laravel-worker.conf:
[program:laravel-worker]
process_name=%(program_name)s_%(process_num)02d
command=php /var/www/app/artisan queue:work redis --queue=high,default,emails --sleep=3 --tries=3 --max-time=3600 --max-jobs=1000
autostart=true
autorestart=true
stopasgroup=true
killasgroup=true
user=www-data
numprocs=4
redirect_stderr=true
stdout_logfile=/var/log/laravel-worker.log
stopwaitsecs=3600Затем:
sudo supervisorctl reread
sudo supervisorctl update
sudo supervisorctl start laravel-worker:*
sudo supervisorctl statusПосле деплоя нового кода старые воркеры держат в памяти старые классы. Команда php artisan queue:restart отправляет всем воркерам сигнал корректно завершиться после текущей задачи — Supervisor поднимет новые с обновлённым кодом.
Failed jobs: что делать с упавшими задачами
Если задача исчерпала все tries, она попадает в таблицу failed_jobs с полным трейсом исключения. Просмотр и управление:
# Список упавших
php artisan queue:failed
# Повторить конкретную
php artisan queue:retry 5
# Повторить все
php artisan queue:retry all
# Удалить одну
php artisan queue:forget 5
# Очистить таблицу
php artisan queue:flushНа проде стоит мониторить эту таблицу — рост числа записей сигнализирует о деградации. Простой алёрт через крон:
// app/Console/Commands/MonitorFailedJobs.php
public function handle(): int
{
$count = DB::table('failed_jobs')->count();
if ($count > 50) {
// Уведомление в Slack / Telegram / почту
\Notification::route('slack', config('alerts.slack'))
->notify(new FailedJobsAlert($count));
}
return self::SUCCESS;
}Отдельный класс ошибок — ModelNotFoundException. Если в Job передан $orderId, а к моменту выполнения заказ удалён, Job упадёт в failed. Чтобы тихо пропускать такие случаи, добавьте свойство:
public bool $deleteWhenMissingModels = true;Rate limiting, batches и уникальные задачи
Если внешний API лимитирует на 60 запросов в минуту, воркер с 8 потоками легко превысит лимит. Решение — middleware RateLimited:
use Illuminate\Cache\RateLimiting\Limit;
use Illuminate\Queue\Middleware\RateLimited;
use Illuminate\Support\Facades\RateLimiter;
// В сервис-провайдере boot()
RateLimiter::for('external-api', function () {
return Limit::perMinute(60);
});
// В Job
public function middleware(): array
{
return [new RateLimited('external-api')];
}Job, превысивший лимит, не упадёт — он вернётся в очередь с автоматической задержкой.
Batches — группа задач с общим колбэком на завершение. Например, отправить 10 000 писем и узнать, когда всё закончилось:
use Illuminate\Bus\Batch;
use Illuminate\Support\Facades\Bus;
$jobs = User::query()
->where('subscribed', true)
->pluck('id')
->map(fn ($id) => new SendNewsletter($id))
->all();
Bus::batch($jobs)
->name('Newsletter 2026-05')
->allowFailures()
->then(fn (Batch $batch) => \Log::info("Done: {$batch->processedJobs()} of {$batch->totalJobs}"))
->catch(fn (Batch $batch, \Throwable $e) => \Log::error($e->getMessage()))
->finally(fn (Batch $batch) => cache()->forget('newsletter:in_progress'))
->onQueue('emails')
->dispatch();Для batches нужна таблица job_batches: php artisan queue:batches-table && php artisan migrate.
Уникальные задачи — защита от двойного выполнения. Если пользователь дважды кликнул «Отправить» — в очередь попадут два одинаковых Job. Реализация:
use Illuminate\Contracts\Queue\ShouldBeUnique;
class GenerateReport implements ShouldQueue, ShouldBeUnique
{
public int $uniqueFor = 3600; // секунд блокировки
public function uniqueId(): string
{
return 'report:' . $this->reportId;
}
}Для работы ShouldBeUnique нужен драйвер кеша, поддерживающий атомарные блокировки — Redis, Memcached или database.
Чеклист для прода
- Драйвер —
redis(илиsqsна AWS), неdatabaseпри больших объёмах - В Job передаём ID моделей, не сами модели
- Используем
afterCommit()для задач, зависящих от транзакции $tries,$timeout,$backoffзаданы явно — не полагаемся на дефолты- Воркеры запущены через Supervisor,
numprocsподобран под нагрузку - В CI/CD после деплоя —
queue:restart - Мониторинг
failed_jobsи алёрт при росте - Тяжёлые задачи в отдельной очереди (
--queue=high,default) — чтобы массовая рассылка не блокировала срочные - Для внешних API —
RateLimitedmiddleware - Для критичных операций —
ShouldBeUniqueс понятнымuniqueId()
Очередь — не «бесплатное» решение: она требует Supervisor, мониторинга и аккуратной работы с транзакциями. Зато вытаскивает медленные операции из HTTP-запросов и спасает приложение от таймаутов.
